Text (Sentence) Classification¶
Text Pool (Corpus)¶
Transcript version of:
- President Obama 2009 Inaugural Speech
- 2012 Presidential Candidate Gov Mitt Romney campaign Speech
Snapshot of the Transcript versions
Game Plan¶
- Every sentence extracted and labelled by the speaker's name and saved as a data-frames.
Both data matrix concatenated to create the corpus in data-frame format (Columns: Sentence and Speaker)
Text cleaning: removePunctuation(), removeNumbers(), removeSparseTerms() etc
Reshuffle the order of observation randomly and spilt into Training set and Test set data and pass it through different algorithms.
Do prediction for the test data
Classification Algorithm¶
- Suport Vector Machine (SVM)
- Random Forest (RF)
- Decision Tree (Tree)
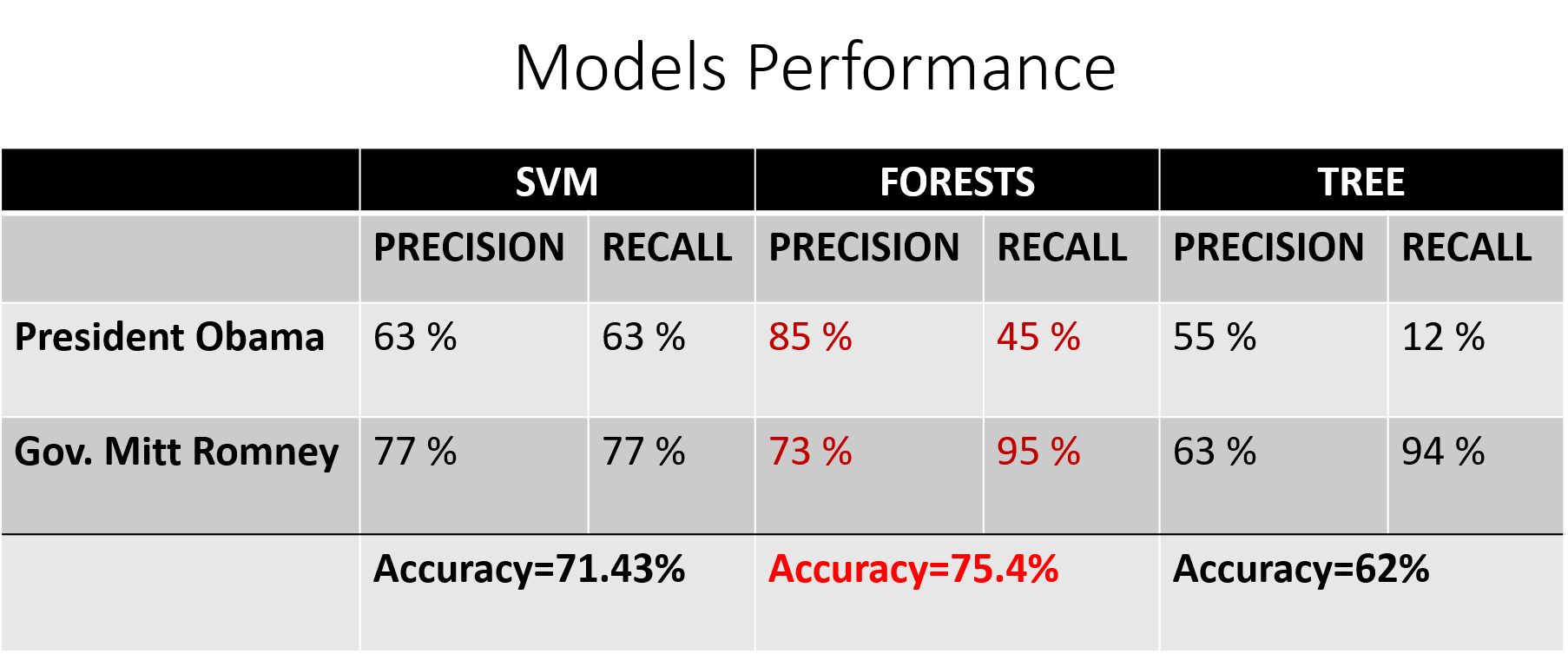
Precision: Among the total sentences predicted to be Pres.Obma’s, 85% of them are factually correct. On the other hand, 73 % of Gov Romney’s predicted sentences are factually correct.
Recall: 95 % of Gov Romney’s sentence are predicted correctly. Whereas, 45% of Pres. Obama’s speech sentences are managed to be predicted correctly which is below a random guess.
Accuracy: the selected model Random Forest had a 75 percent accuracy. This means that any randomly selected sentence has a 75 % chance of being labelled to the correct speaker.